
June 2026 · AI Foundation Roadmap · Part 2 of the CV Series
In Part 1, we covered what computer vision is and where it shows up in the real world. We established that machines can see, and that deep learning is what made that possible at scale.
Now it's time to go one level deeper.
Most computer vision courses jump straight to code. You clone a repository, run a model, get a result, and feel like you've learned something. Then someone asks you why the model failed on a specific input, or how to adapt it to a new domain, and you have no answer. Because you learned to use a tool, not to understand one.
This post is the understanding part. It covers the core concepts, architectures, and tasks that serious CV practitioners know, written for someone who doesn't have a PhD but is serious about building real things.
What Is Deep Learning for Computer Vision?
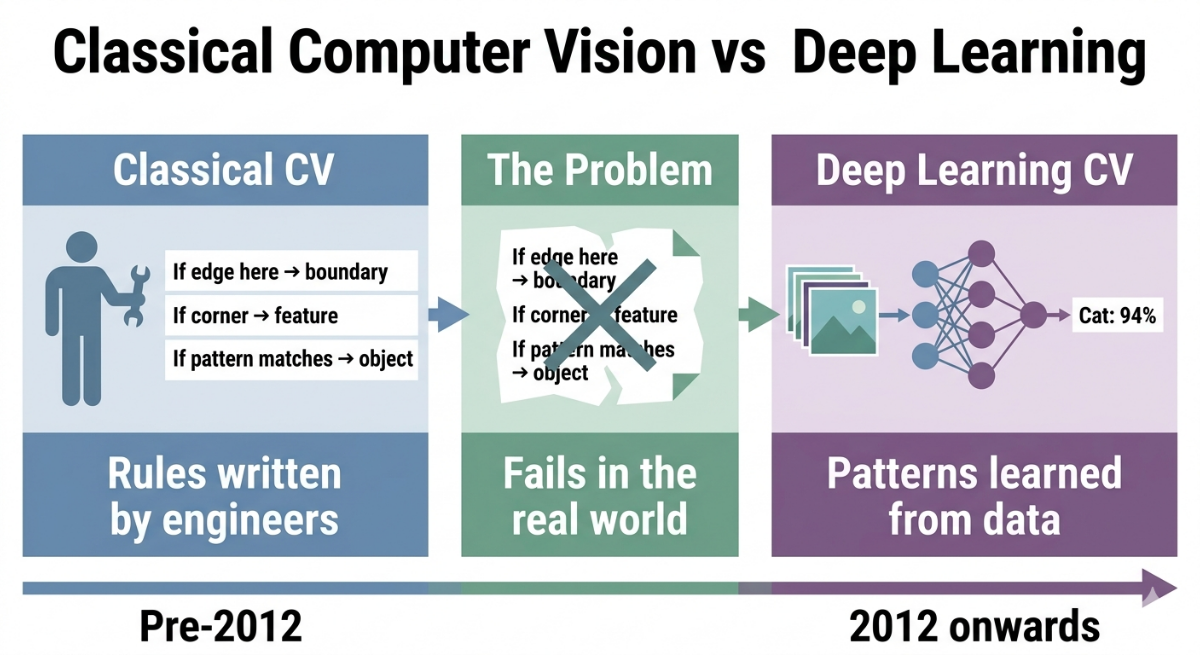
Deep learning for computer vision is the application of neural networks (specifically deep ones, with many layers) to visual data. Instead of hand-coding rules for what a cat looks like, you train a model on millions of labeled images and let it learn the visual patterns itself.
This distinction matters. Classical computer vision was engineering-heavy: detect edges using this algorithm, match shapes using that formula, combine the results with these thresholds. It worked in controlled conditions. It fell apart in the real world, where lighting changes, objects overlap, angles vary, and no two images of the same thing look exactly alike.
Deep learning solved this by replacing hand-crafted rules with learned representations. The model sees enough examples that it builds its own internal understanding of what visual patterns matter, and which ones don't. The result is systems that generalize to conditions they've never explicitly seen before.
Computer vision and machine learning are deeply intertwined for this reason. Modern CV is machine learning applied to pixels. You can't understand one without the other.
The Foundation: Convolutional Neural Networks (CNNs)
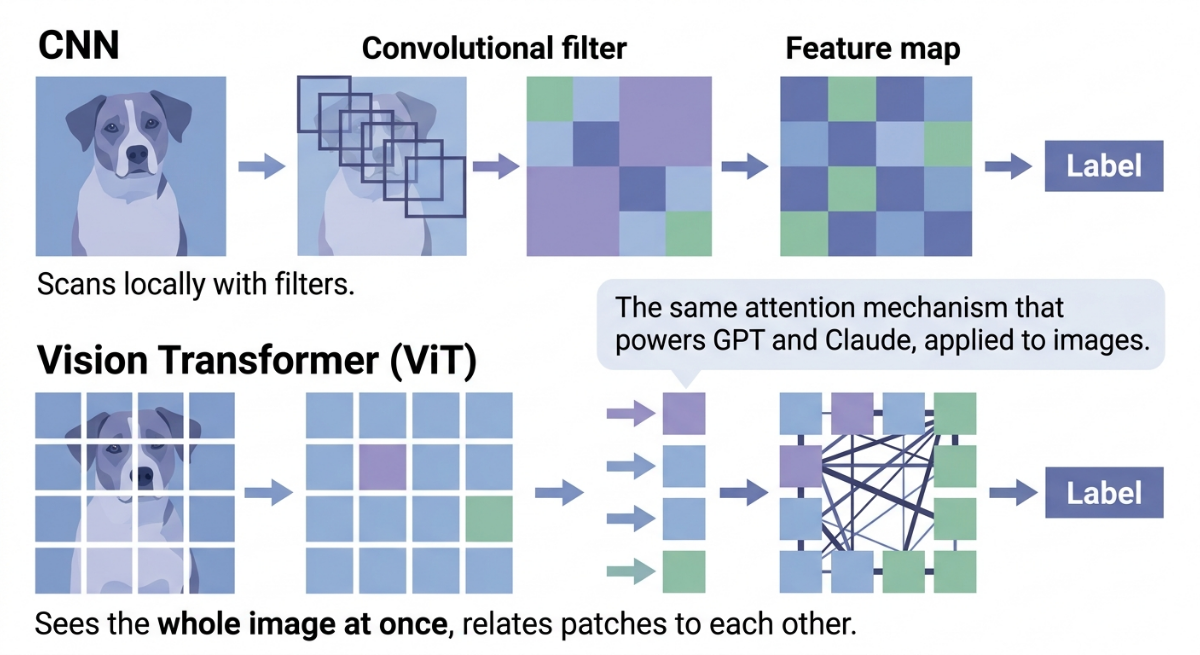
If there's one concept that defines modern computer vision, it's the Convolutional Neural Network (CNN).
A CNN is a type of neural network designed specifically for grid-structured data, which is exactly what images are. It processes visual information through a series of layers, each one learning to detect increasingly complex patterns.
Here's what happens layer by layer:
- Convolutional layers: small filters slide across the image and detect local patterns, edges, textures, gradients. Each filter learns to respond to a specific visual feature. Early layers detect simple things (a horizontal edge). Later layers combine those into complex things (an eye, a wheel, a tumor outline).
- Pooling layers: reduce the spatial size of the representation, keeping the most important information and discarding fine-grained position details. This makes the model more robust to small shifts and distortions in the input.
- Fully connected layers: at the end of the network, the learned features are flattened and combined to produce a final output, a class label, a bounding box, a probability score.
The key insight is that CNNs exploit the structure of images. Nearby pixels are related. The same edge pattern appears in many places. Features that matter in one part of the image often matter in others. CNNs are designed to take advantage of all of this, which is why they outperform general neural networks on visual tasks by a wide margin.
The CNN Architectures Worth Knowing
You don't need to memorize these. But knowing the lineage tells you a lot about how the field evolved:
- AlexNet (2012): the model that started the deep learning revolution in CV. Won ImageNet by a margin that shocked the research community and triggered a decade of rapid progress.
- VGG (2014): showed that depth matters. Deeper networks with small filters consistently outperformed shallower ones with large filters.
- ResNet (2015): introduced residual connections, allowing networks to be trained with hundreds of layers without the gradients vanishing. Still widely used as a backbone today.
- EfficientNet (2019): showed that scaling width, depth, and resolution together in a principled way produces better models with fewer parameters.
Each of these is a chapter in the story of how researchers figured out how to make deep networks learn better, train faster, and generalize further.
Vision Transformers: The Architecture That Changed Everything (Again)
CNNs dominated computer vision for nearly a decade. Then, in 2020, a paper called "An Image is Worth 16x16 Words" introduced the Vision Transformer (ViT), and everything shifted again.
The idea was simple in retrospect: take the transformer architecture that had transformed NLP (the same architecture behind GPT and BERT) and apply it to images. Instead of processing images with convolutional filters, split the image into small patches, treat each patch like a token, and let the attention mechanism figure out which patches are relevant to which others.
The result was models that outperformed CNNs on large-scale benchmarks, scaled better with more data and compute, and transferred more effectively across domains.
In 2026, the best CV models are typically transformer-based or hybrid (combining convolutional and attention mechanisms). Understanding the transformer is no longer optional if you're working seriously with computer vision.
Core Computer Vision Tasks in Depth
In Part 1, we listed the main CV tasks. Here we go one level deeper into how they actually work.
Image Classification
The simplest CV task: given an image, output a label. Cat or dog. Benign or malignant. Defective or acceptable.
Under the hood, the model outputs a probability distribution across all possible classes. The class with the highest probability is the prediction. Training uses a loss function (cross-entropy) that penalizes the model when its confidence in the correct class is low.
Classification is the entry point for most CV practitioners and the task that most computer vision courses start with. It's also the foundation everything else is built on.
Object Detection
Classification tells you what is in an image. Object detection tells you what and where, for every object in the scene simultaneously.
This is significantly harder. The model has to solve two problems at once: identify the class of each object and predict the coordinates of a bounding box around it.
YOLO (You Only Look Once) is the most widely used object detection architecture in production. The name describes its approach: rather than scanning the image multiple times with a sliding window, YOLO processes the entire image in a single forward pass and predicts all bounding boxes at once. This makes it fast enough for real-time applications, which is why it's the default for use cases like security cameras, autonomous vehicles, and manufacturing inspection lines.
YOLO computer vision has become almost synonymous with production object detection. If you're building a real-time CV system, you're probably starting with YOLO.
Image Segmentation
Segmentation goes further than detection. Instead of a bounding box, it identifies exactly which pixels belong to each object.
There are two main types:
- Semantic segmentation: every pixel gets a class label (road, sky, person, car), but individual instances aren't distinguished. Two people in the same image are both labeled "person."
- Instance segmentation: distinguishes individual objects of the same class. Person 1, Person 2. Car 1, Car 2. Each instance gets its own pixel mask.
Segmentation is computationally heavier than detection but produces much richer outputs. It's the standard in medical imaging (outlining a tumor precisely), autonomous driving (understanding the drivable surface at the pixel level), and augmented reality.
Object Detection in Machine Learning: Why It's Hard
A question worth addressing directly: what is object detection in machine learning?
Object detection is a structured prediction problem. The model doesn't just output a single label. It outputs a variable number of bounding boxes, each with a class label and a confidence score, for an image it's never seen before.
The challenges are real: objects overlap, objects appear at different scales, the same object looks different from different angles, and some objects are partially occluded. Modern detection models handle all of this through anchor boxes, non-maximum suppression, and multi-scale feature extraction. These aren't just implementation details. They're solutions to fundamental problems that took years of research to crack.
Transfer Learning: The Practical Secret of Modern CV
Here's something most introductions skip: almost nobody trains a computer vision model from scratch in production.
Training a model from scratch requires millions of labeled images, weeks of compute, and significant expertise. Most teams don't have any of that. What they have is a specific problem (detect defects in this type of circuit board) and a few thousand labeled examples.
Transfer learning solves this. You start with a model that's already been trained on a massive dataset (ImageNet, with 1.2 million images across 1,000 classes) and fine-tune it on your specific task. The model already knows how to detect edges, textures, shapes, and high-level visual features. You're teaching it to apply those capabilities to your domain.
This is why OpenCV and Hugging Face are so central to practical CV work. They give you access to pre-trained models that you can fine-tune with a fraction of the data and compute that training from scratch would require.
Transfer learning is the bridge between research and production. It's also the concept that makes computer vision accessible to practitioners who don't work at Google or Meta.
Computer Vision in Healthcare
Computer vision in healthcare is one of the most consequential applications of the technology, and one of the most instructive examples of what CV can and can't do.
The successes are real. CV models now match or exceed specialist-level accuracy on specific diagnostic tasks: detecting diabetic retinopathy from retinal scans, identifying cancerous nodules in CT scans, classifying skin lesions from photographs. These aren't demos. They're FDA-cleared products in clinical use.
The limits are equally real. CV models are brittle outside their training distribution. A model trained on scans from one hospital may fail on scans from another hospital that uses slightly different imaging equipment. A model that performs brilliantly on a benchmark may miss cases that a human radiologist would catch, because the human brings context the model doesn't have.
Computer vision in healthcare is not "AI replaces the doctor." It's "AI handles high-volume screening so specialists can focus on the cases that need them." That's a meaningful and genuine contribution. It's also a more honest description of what the technology actually does.
Computer Vision in Retail
Computer vision in retail is where the technology has arguably seen its fastest adoption.
The applications range from the mundane to the genuinely transformative:
- Shelf monitoring: cameras detect empty shelves and trigger restocking alerts automatically, eliminating manual shelf-checking walks.
- Checkout-free stores: Amazon Go and similar concepts use a combination of computer vision and sensor fusion to track what customers pick up and charge them automatically on exit.
- Loss prevention: CV models identify behaviors associated with shoplifting without requiring human surveillance staff to monitor every feed.
- Customer analytics: foot traffic patterns, dwell time at specific displays, queue length monitoring. All extracted from camera feeds without storing personal data.
- Visual search: a customer photographs a product they saw somewhere and the retailer's app finds the same or similar items in the catalog.
Computer vision in retail works because retail environments are relatively controlled (fixed camera positions, known product categories, consistent lighting) compared to outdoor or medical environments. That control makes models more reliable and easier to deploy at scale.
OpenCV: The Tool Every CV Practitioner Knows
No CV post is complete without mentioning OpenCV.
OpenCV (Open Source Computer Vision Library) is the foundational library for computer vision in Python (and C++). It's been in development since 1999. It underpins production systems across every industry. And despite being older than most of the deep learning frameworks that have emerged since, it remains essential.
What OpenCV does:
- Image loading, saving, and format conversion
- Geometric transformations (resize, rotate, crop, warp)
- Color space conversions (RGB to grayscale, HSV, LAB)
- Classical CV operations: edge detection (Canny), thresholding, contour finding, morphological operations
- Video capture and processing from cameras and files
- Camera calibration and 3D reconstruction
OpenCV is not a deep learning framework. It doesn't train neural networks. What it does is handle all the image manipulation and preprocessing that happens before and after the model, and for classical CV tasks, it often handles the whole pipeline on its own.
In practice, most production CV systems use OpenCV for preprocessing and a deep learning framework (PyTorch, TensorFlow) for the model. They're complementary, not competing.
Where to Go From Here
If this roadmap has done its job, you now have a mental model of how deep learning for computer vision actually works. You understand CNNs, why Vision Transformers changed the field, what the core tasks are and how they differ, why transfer learning is the practical default, and where CV is creating real value in industries like healthcare and retail.
The next step is building. The concepts in this post are the foundation. The computer vision courses and resources worth your time are the ones that take you from this understanding into actual implementation, not the ones that hand you a pre-built notebook and call it learning.
Start with image classification. Use a pre-trained ResNet or EfficientNet via Hugging Face or torchvision. Fine-tune it on a dataset that interests you. Then move to object detection with YOLO. Then build something that runs on real data, even if it's just your laptop camera.
That path, understanding first and code second, is how practitioners develop judgment. And judgment is what separates the people who can use CV tools from the people who can build with them.
Key Takeaways
- Deep learning for computer vision replaced hand-crafted rules with learned visual representations, trained on large labeled image datasets.
- CNNs are the foundational architecture: convolutional layers detect local patterns, pooling layers add robustness, and fully connected layers produce the final output.
- Vision Transformers (ViTs) apply attention mechanisms to image patches and now match or outperform CNNs on most large-scale benchmarks.
- Core CV tasks (classification, object detection, segmentation) differ in output complexity and computational cost. YOLO is the production standard for real-time object detection.
- Transfer learning is how most production CV systems are built: start from a pre-trained model, fine-tune on your specific task.
- OpenCV handles image preprocessing and classical CV operations. Deep learning frameworks handle the models. In production, you use both.
- Computer vision in healthcare and retail are two of the highest-impact deployment areas, with meaningfully different constraints and failure modes.
Frequently Asked Questions
Frequently Asked Questions

Javier Aguirre
Teaching AI from production reality, not hype.
Build your AI Foundations
Get the free checklist that production engineers use to avoid these common RAG pitfalls.
Get the Free Guide