
In Part 1, we covered what NLP is and why it matters. We talked about the 70 years of research that most people skip. We made the case that LLMs are the top floor of a building, and NLP is the foundation.
Now it's time to walk through that building.
This post is your roadmap to the core natural language processing techniques. Not a deep dive into every room (that would take a book). But a clear map so you know what exists, why it matters, and how the pieces connect. By the end, you'll understand how NLP actually works under the hood, layer by layer, the same way the engineers who build these systems do.
What Are NLP Techniques, Exactly?
When people ask "what is NLP techniques?", they usually mean one of two things: either the specific tasks NLP can perform (sentiment analysis, translation, etc.) or the underlying methods used to make those tasks work (tokenization, embeddings, parsing, etc.).
Both matter. And they're related.
Think of it this way: NLP tasks are the what, the problem being solved. NLP techniques are the how, the machinery that makes it happen. You need to understand both, because in production, knowing that you want to do "sentiment analysis" is only half the job. The other half is knowing which technique to reach for, and why.
This roadmap covers both.
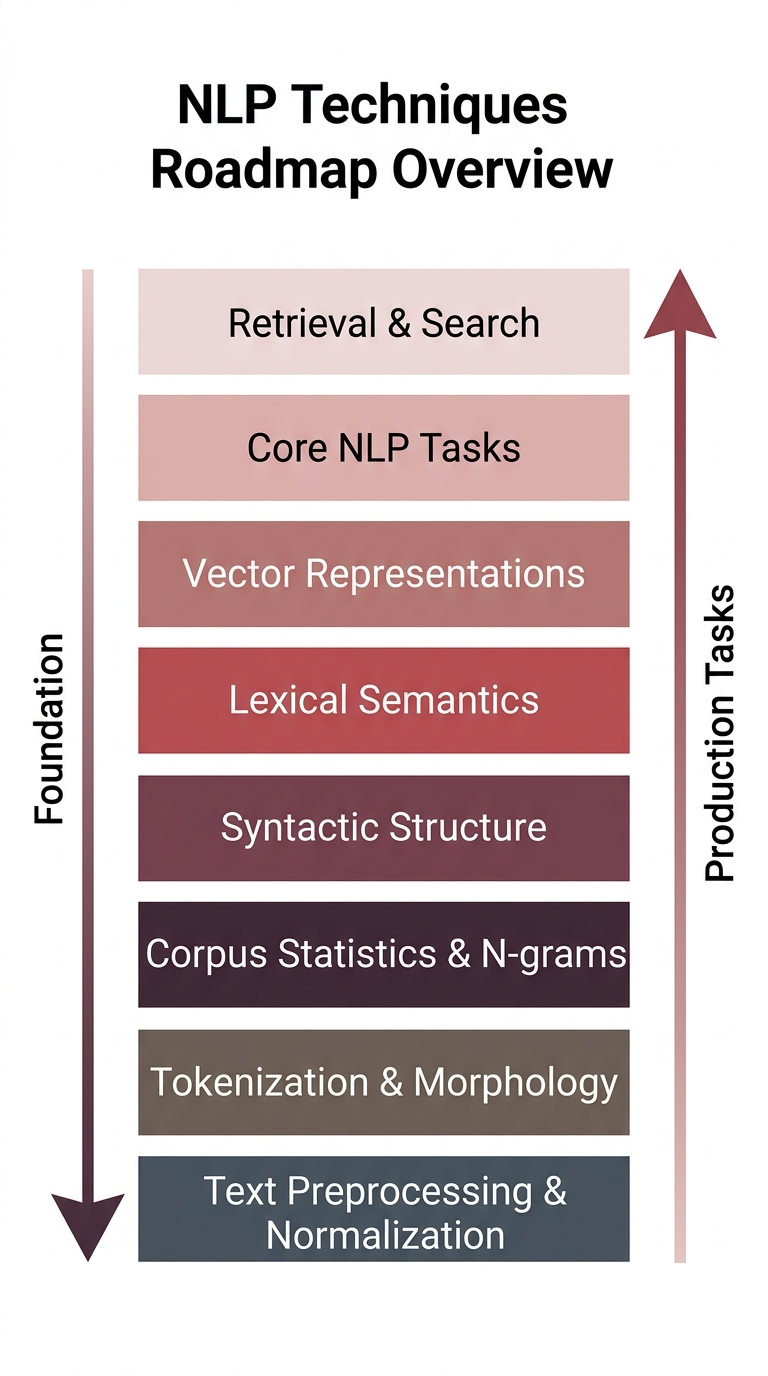
The Stack: How NLP Techniques Are Layered
Modern NLP is built in layers. Each layer builds on the one beneath it. Understanding this is critical, because it explains why NLP models behave the way they do (and why they fail the way they do).
Here's the stack, from bottom to top:
Text Preprocessing & Normalization
↓
Tokenization & Morphology
↓
Corpus Statistics & N-grams
↓
Syntactic Structure
↓
Lexical Semantics
↓
Vector Representations
↓
Core NLP Tasks
↓
Retrieval & SearchLet's walk through each one.
Layer 1: Text Preprocessing and Normalization
Before any model touches your data, the text has to be cleaned. This sounds boring. It is also the source of more production bugs than any other stage.
Real-world text is messy. HTML tags, emojis, unicode quirks, inconsistent casing, special characters. An NLP model trained on clean text will silently fail on dirty input. Most beginners don't find this out until something breaks in production.
The key operations at this layer:
- Lowercasing and unicode normalization: standardizing text before any processing. Seemingly trivial, frequently the source of subtle bugs.
- Stopword removal: filtering high-frequency words with low semantic content (the, a, is). Context-dependent: wrong for search, sometimes useful for topic modeling.
- Stemming vs. lemmatization: stemming is fast and crude (running → run); lemmatization is linguistically correct (better → good). You need to know when each is appropriate.
- Text cleaning pipelines: handling HTML, special characters, emojis, and noise in real-world data.
These aren't glamorous. They're also non-negotiable. Every serious NLP project starts here.
Layer 2: Tokenization and Morphology
Tokenization is where NLP actually begins: splitting text into units a model can process.
Most people assume tokenization means splitting on spaces. That works for English in ideal conditions. It breaks down fast everywhere else, contractions, punctuation, compound words, languages without spaces (Chinese, Japanese), and the messy reality of user-generated content.
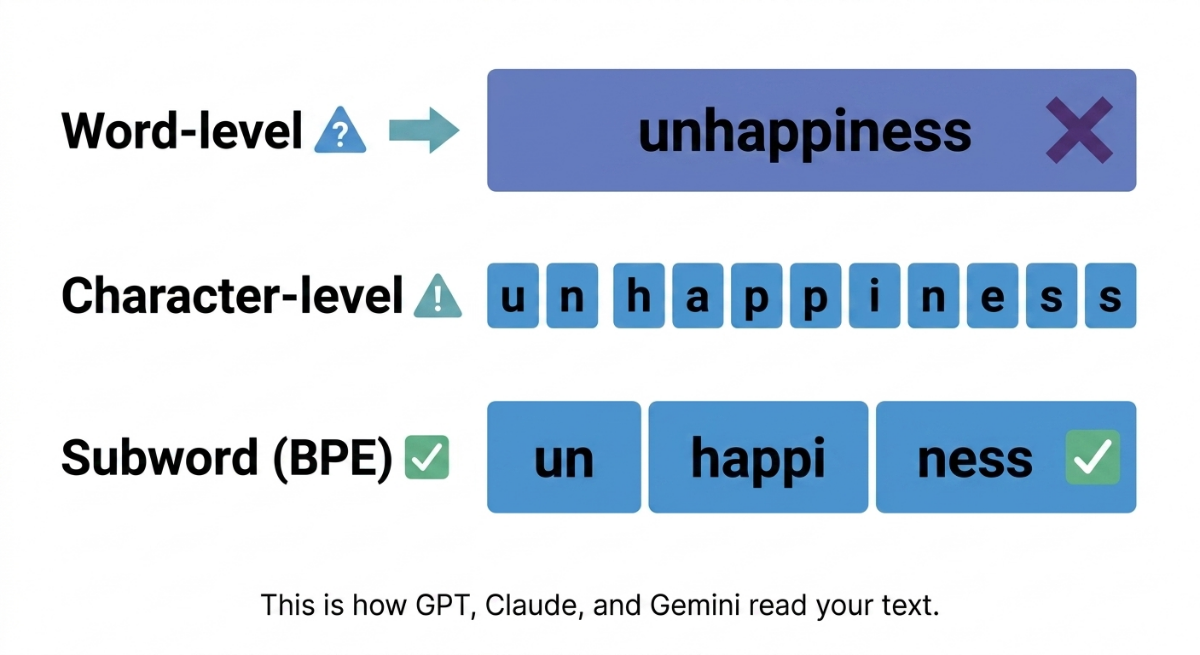
Modern NLP models don't tokenize at the word level. They use subword tokenization, methods like BPE (Byte-Pair Encoding), WordPiece, and SentencePiece that break words into meaningful sub-units. This is how every major LLM (GPT, Claude, Gemini) handles text. Understanding tokenization means understanding why a model behaves the way it does when it sees unusual words, typos, or languages it wasn't primarily trained on.
Morphological analysis, understanding word structure, matters especially for languages with complex inflection. English is morphologically simple. Turkish, Finnish, and Arabic are not. The same concept applies: without understanding how words are built, models fail on the edges of any language.
The out-of-vocabulary (OOV) problem is why subword methods exist. When a model encounters a word it's never seen, it needs a way to handle it. Subword tokenization is the answer: even novel words can be decomposed into familiar pieces.
Layer 3: Corpus Statistics and N-grams
Before neural networks dominated NLP, the field ran on statistics. That era produced tools and concepts that are still in use today, and that anyone serious about NLP basics needs to understand.
N-grams are sequences of n tokens. A bigram is two consecutive words. A trigram is three. Before neural language models, n-gram models were the standard approach to predicting the next word in a sequence. They're still used in production systems where speed and interpretability matter.
TF-IDF (Term Frequency, Inverse Document Frequency) weights words by how distinctive they are to a document. A word that appears frequently in one document but rarely elsewhere is probably important to that document. TF-IDF operationalizes this intuition. It's still used in production search systems, right now, in 2026.
Language model perplexity, how "surprised" a model is by a given text, is a core evaluation metric that predates LLMs and still matters for assessing how well a model captures the structure of language.
If you've only ever worked with neural models and embeddings, adding corpus statistics to your toolkit will immediately make you a better practitioner.
Layer 4: Syntactic Structure
Syntax is grammar at the machine level.
When a human reads "The dog bit the man," we instantly know who did the biting. When a machine processes that sentence, it needs to work that out explicitly, and syntactic analysis is how it does it.
The main techniques:
- Part-of-speech (POS) tagging: labeling each token with its grammatical role, noun, verb, adjective, preposition. The input to most downstream tasks.
- Dependency parsing: modeling the grammatical relationships between words. Who is the subject? What is the object? Which noun does the adjective modify?
- Constituency parsing: breaking sentences into nested phrases (noun phrase, verb phrase). Less common in production today, but important for understanding how models represent sentence structure.
Here's the thing many people miss: LLMs don't parse sentences the way a classical NLP system does. They learn syntactic patterns implicitly from data. But when an LLM makes an error that seems grammatically strange, it's often a syntactic failure. Understanding syntax gives you the vocabulary to diagnose those failures, and to build hybrid systems that fix them.
Layer 5: Lexical Semantics — How Words Carry Meaning
Words are not just labels. They carry relationships.
Dog and puppy are related by degree. Hot and cold are opposites. Vehicle is a broader category that contains car. These relationships are the structure of meaning in language, and understanding them is central to NLP.
Word sense disambiguation (WSD) is the challenge of resolving which meaning a word carries in context. "Bank" means a financial institution in one sentence and a riverbank in another. Humans do this effortlessly. Machines have to learn it explicitly, and getting it wrong breaks downstream tasks.
Lexical resources like WordNet and FrameNet are structured knowledge bases that map these relationships. They predate neural approaches by decades and still complement modern models, especially when working with specialized domains like legal or biomedical text where precision matters more than general fluency.
Understanding lexical semantics is what separates practitioners who can debug NLP failures from those who just know that something went wrong.
Layer 6: Vector Representations — Teaching Machines What Words Mean
This is where NLP deep learning starts to enter the picture, and where things get mathematically interesting.
The fundamental challenge is this: machines work with numbers. Language is made of symbols. How do you bridge that gap in a way that preserves meaning?
The evolution of the answer is one of the most important stories in AI:
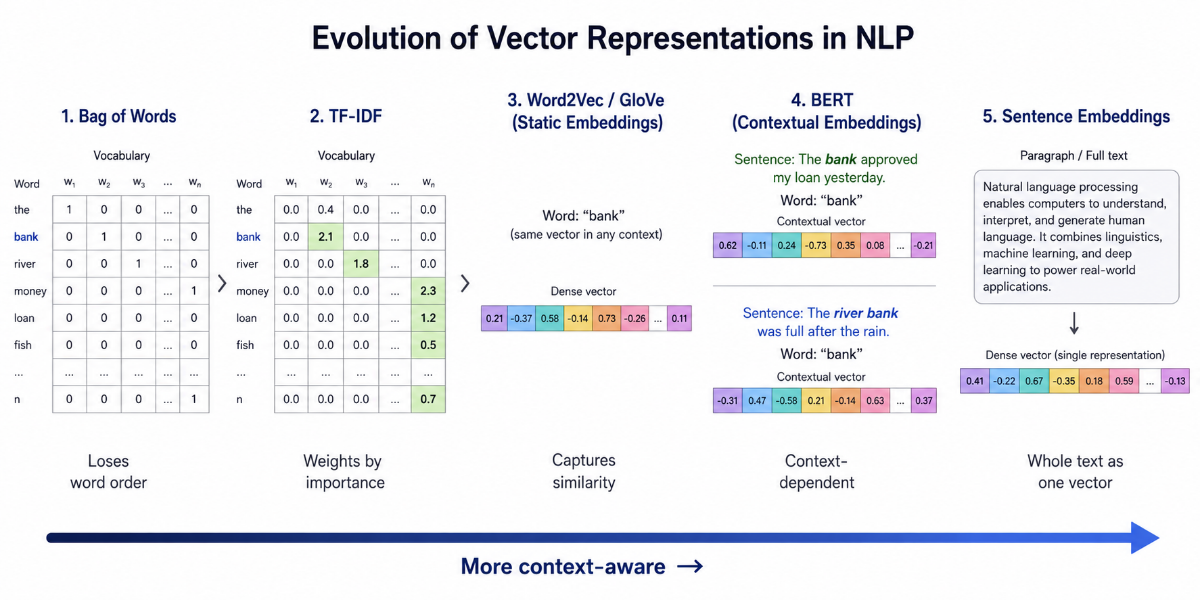
Bag of Words (BoW): represent text as a vector of word counts. Simple, loses word order, surprisingly effective for classification. Still used.
TF-IDF vectors: same idea, but weight each word by its distinctiveness. Better signal-to-noise ratio for retrieval tasks.
Static word embeddings, Word2Vec, GloVe, FastText. Dense vector representations trained on large corpora that capture semantic similarity. "King" minus "man" plus "woman" approximately equals "queen." This wasn't programmed, the model learned it from patterns in text. A genuine breakthrough.
Contextual embeddings, the innovation that made modern NLP. The same word gets a different vector depending on context. "Bank" in a financial context gets a different representation than "bank" in a geographic one. BERT introduced this, and it changed everything.
Sentence and document embeddings: representing entire texts as single vectors. The foundation of semantic search and retrieval-augmented generation (RAG). When you ask a RAG system a question and it finds the right chunk of text to answer it, sentence embeddings are doing that work.
Understanding this progression, from bag of words to contextual embeddings, is essential for anyone working with NLP models seriously. It explains not just what these systems do, but why they work.
Layer 7: Core NLP Tasks in Production
Now we arrive at the tasks themselves, the problems NLP is deployed to solve at scale.
Text Classification
Assigning a category to a document. Spam detection, topic labeling, intent recognition, content moderation. One of the most widely deployed NLP capabilities in existence.
Sentiment Analysis
Determining the emotional tone of text (positive, negative, neutral) at the document level or at the level of specific aspects ("the battery life is great but the camera is disappointing"). Used in brand monitoring, product review analysis, financial signal extraction.
Named Entity Recognition (NER)
Identifying and labeling spans of text as people, organizations, locations, dates, and other entity types. The system reading a news article that automatically extracts that "Apple" is a company, "Tim Cook" is a person, and "Cupertino" is a location, that's NER.
Relation Extraction
Going beyond NER to understand what entities do to each other. "Apple acquired Beats," NER identifies Apple and Beats as organizations; relation extraction understands that one acquired the other.
Coreference Resolution
Linking pronouns and noun phrases to the entities they refer to. "Tim Cook announced the product. He said it would ship in November." Coreference resolution connects "He" to Tim Cook and "it" to the product. Often a bottleneck in information extraction pipelines.
Text Summarization
Compressing a long document into a shorter version while preserving key information. Both extractive (selecting existing sentences) and abstractive (generating new ones) approaches exist. The same capability that lets AI tools summarize a 30-page report in seconds.
Machine Translation
Converting text between languages. The backbone of tools like Google Translate. Also one of the oldest NLP tasks, and the one that drove many of the field's most important technical advances.
Question Answering
Enabling a system to find and return an answer to a natural language question from a document or knowledge base. The foundation of most enterprise search and knowledge management tools.
What Is NLP in Machine Learning?
A question worth addressing directly: what is NLP in machine learning?
NLP sits inside machine learning, which sits inside AI. But the relationship is more than just containment, it's about method.
Classical NLP relied on hand-written rules: if the sentence contains "not," reverse the sentiment. This worked for simple cases and broke completely on everything else.
Modern NLP is machine learning applied to language. Instead of rules, you train models on large datasets and let them learn the patterns. This shift, from rules to learning, is why NLP improved so dramatically over the past decade, and why the same underlying techniques (embeddings, transformers, attention) now power everything from search engines to large language models.
The important distinction: not all NLP is deep learning. Logistic regression on TF-IDF features is still NLP in machine learning. BM25 retrieval is still NLP. Classical NLP methods are often faster, cheaper, more explainable, and more appropriate than a neural model for well-defined tasks. The mature approach is knowing which tool to reach for, not defaulting to the most complex one available.
NLP Python: Where the Code Lives
Most NLP work happens in Python. That's not an opinion, it's the current reality of the ecosystem.
The core libraries you'll encounter:
- spaCy: industrial-strength NLP. Tokenization, POS tagging, NER, dependency parsing. Fast, production-ready, opinionated in the best way.
- NLTK: the academic library. Older, broader, slightly clunkier. Still useful for learning fundamentals and accessing lexical resources like WordNet.
- Hugging Face Transformers: the standard library for working with modern NLP models. Pre-trained models for every task, fine-tuning pipelines, model hub with thousands of ready-to-use checkpoints.
- scikit-learn: for classical ML applied to NLP, TF-IDF vectorization, classification, clustering.
- Gensim: topic modeling (LDA) and static word embeddings (Word2Vec, FastText).
NLP Python is where the techniques become real. The concepts in this roadmap aren't abstract, every one of them has a corresponding library, function, and dataset you can work with today.
NLP Projects: Where Learning Becomes Skill
Reading about NLP techniques is useful. Building NLP projects is what actually makes you capable.
Here are five projects that cover the core skills, roughly ordered from beginner to intermediate:
1. Sentiment classifier on product reviews: classic binary classification. Teaches preprocessing, TF-IDF, and basic model evaluation.
2. Named entity recognizer on news articles: work with spaCy's NER pipeline. Teaches sequence labeling and evaluation with precision/recall.
3. Text summarizer: start extractive (select top sentences by TF-IDF score), then compare to an abstractive approach using a pre-trained model.
4. Semantic search engine: index a document corpus with sentence embeddings and retrieve results by cosine similarity. This directly mirrors how RAG works.
5. End-to-end text classification pipeline: raw data in, labeled predictions out, with preprocessing, vectorization, training, and evaluation. Treat it like a production system.
Each of these projects forces you to confront real problems: messy data, edge cases, evaluation failures, and the gap between benchmark performance and real-world performance. That gap is where engineering maturity develops.
Key Takeaways
- NLP techniques are layered. Text preprocessing, tokenization, syntax, semantics, and vector representations all feed into the tasks you actually deploy.
- Static word embeddings were a breakthrough. Contextual embeddings were the next one. Understanding both tells you how we got to modern NLP models.
- NLP in machine learning means learning patterns from data, not writing rules. But classical NLP methods are still relevant and often the right tool.
- Core NLP tasks (classification, NER, summarization, question answering) are in active production use right now, across every major industry.
- NLP Python has a mature ecosystem. spaCy, Hugging Face, scikit-learn. Start there.
- Building NLP projects is how abstract knowledge becomes real capability.
Frequently Asked Questions

Javier Aguirre
Teaching AI from production reality, not hype.
Build your AI Foundations
Get the free checklist that production engineers use to avoid these common RAG pitfalls.
Get the Free Guide