
Reading a news article, a human instantly knows that "Apple" refers to a company, "Tim Cook" is a person, and "Cupertino" is a place. We don't think about it. The context makes it obvious.
Teaching a machine to do the same thing is the job of named entity recognition.
It's one of the most widely used NLP tasks in production systems today, and for good reason. Before you can analyse what a document says about a company, extract key facts from a contract, or build a knowledge graph from millions of news articles, you need to know who and what the text is actually referring to. Named entity recognition is how you find out.
What Is Named Entity Recognition?
Named entity recognition (NER) is the NLP task of locating and classifying named entities in text: the specific real-world objects that a piece of text refers to, such as people, organisations, locations, dates, and quantities.
Given the sentence:
"Elon Musk announced that Tesla would open a new factory in Berlin by March 2025."
A NER system would identify:
- Elon Musk → PERSON
- Tesla → ORGANIZATION
- Berlin → LOCATION
- March 2025 → DATE
NER is not just about finding proper nouns. It's about identifying which proper nouns are meaningful entities and what type they are. The output is a structured set of labelled spans: a start position, an end position, and an entity type for each entity found in the text.
This makes NER a form of information extraction: the broader task of pulling structured facts out of unstructured text. NER is typically one of the first steps in an information extraction pipeline, because you need to know what entities are present before you can do anything more sophisticated with them.

What Is a Named Entity?
A named entity is a real-world object that can be referred to by a proper name. The most common entity types are:
| Entity type | Examples |
|---|---|
| PERSON | Elon Musk, Marie Curie, Barack Obama |
| ORGANIZATION | Tesla, the United Nations, Harvard University |
| LOCATION / GPE | Berlin, California, the Amazon River |
| DATE | March 2025, last Tuesday, the 1990s |
| TIME | 3pm, midnight, two hours ago |
| MONEY | $4.2 billion, €500, forty pounds |
| PERCENT | 12%, three quarters |
| PRODUCT | iPhone, Windows 11, Model S |
| EVENT | the World Cup, the French Revolution |
| LAW | GDPR, the First Amendment |
Different NER systems use different sets of entity types depending on their intended application. A general-purpose system like spaCy's English model uses around 18 entity types. A biomedical NER system might distinguish between genes, proteins, diseases, and drugs. A financial NER system might specialise in company names, ticker symbols, and financial instruments.
Approach 1: NER with spaCy
spaCy is the most widely used library for NER in Python. It ships with pretrained models for multiple languages that can identify entities out of the box, with no training required.
# pip install spacy
# python -m spacy download en_core_web_sm
import spacy
nlp = spacy.load("en_core_web_sm")
text = """
Apple CEO Tim Cook announced on Tuesday that the company would invest
$430 billion in the United States over the next five years.
The announcement was made at Apple's headquarters in Cupertino, California.
"""
doc = nlp(text)
for ent in doc.ents:
print(f"{ent.text:<30} {ent.label_:<15} {spacy.explain(ent.label_)}")Output:
Apple ORG Companies, agencies, institutions
Tim Cook PERSON People, including fictional
Tuesday DATE Absolute or relative dates or periods
$430 billion MONEY Monetary values, including unit
the United States GPE Countries, cities, states
five years DATE Absolute or relative dates or periods
Apple ORG Companies, agencies, institutions
Cupertino GPE Countries, cities, states
California GPE Countries, cities, statesspaCy's `spacy.explain()` function returns a human-readable description of each entity type, which is helpful when you're getting started.
Visualising Entities
spaCy includes a built-in visualiser that renders entity annotations directly in a Jupyter notebook or browser:
from spacy import displacy
displacy.render(doc, style="ent", jupyter=True)This renders the text with each entity highlighted and labelled inline, useful for quickly inspecting model output and debugging errors.
Choosing the Right spaCy Model
spaCy offers models at different sizes and accuracy levels:
| Model | Size | Speed | Accuracy |
|---|---|---|---|
| `encoreweb_sm` | Small | Fastest | Good |
| `encoreweb_md` | Medium | Fast | Better |
| `encoreweb_lg` | Large | Slower | Best (rule-based) |
| `encoreweb_trf` | Transformer | Slowest | Highest |
For most production use cases, `encorewebmd` or `encoreweblg` offers the best balance of speed and accuracy. Use `encoreweb_trf` (which uses a RoBERTa transformer backbone) when accuracy is the priority and latency is less of a concern.
Approach 2: NER with Hugging Face Transformers
For state-of-the-art NER accuracy, transformer-based models fine-tuned specifically for NER tasks consistently outperform traditional models.
from transformers import pipeline
# Load a pretrained NER pipeline
ner_pipeline = pipeline(
"ner",
model="dbmdz/bert-large-cased-finetuned-conll03-english",
aggregation_strategy="simple"
)
text = """
Elon Musk announced that Tesla would open a new Gigafactory in
Berlin, Germany. The facility is expected to produce 500,000
vehicles per year and will employ around 12,000 people.
"""
entities = ner_pipeline(text)
for entity in entities:
print(f"{entity['word']:<20} {entity['entity_group']:<10} {entity['score']:.2f}")Output:
Elon Musk PER 0.99
Tesla ORG 1.00
Gigafactory ORG 0.87
Berlin LOC 1.00
Germany LOC 1.00The `aggregation_strategy="simple"` parameter merges token-level predictions into full entity spans. Without it, "Elon Musk" would appear as two separate tokens, "Elon" and "Musk", each with their own label.
Transformer-based NER models typically achieve significantly higher accuracy than smaller rule-based or statistical models, particularly on ambiguous entities and longer documents.
Approach 3: Custom NER with spaCy
Pretrained models cover general entity types well, but many real-world applications require domain-specific entities. A legal platform might need to extract clause types and contract parties. A medical platform might need drug names, dosages, and diagnoses. An e-commerce platform might need product names and SKUs.
Training a custom NER model with spaCy requires labelled training data: text with entity spans manually annotated.
import spacy
from spacy.training import Example
from spacy.util import minibatch
import random
# Training data: list of (text, {"entities": [(start, end, label)]})
TRAIN_DATA = [
("Paracetamol 500mg should be taken twice daily.", {
"entities": [(0, 13, "DRUG"), (14, 19, "DOSAGE")]
}),
("The patient was prescribed Ibuprofen 200mg for pain relief.", {
"entities": [(26, 35, "DRUG"), (36, 41, "DOSAGE")]
}),
("Administer Amoxicillin 250mg every eight hours.", {
"entities": [(11, 22, "DRUG"), (23, 28, "DOSAGE")]
}),
("Take Metformin 850mg with meals.", {
"entities": [(5, 14, "DRUG"), (15, 20, "DOSAGE")]
}),
]
# Create a blank English model
nlp = spacy.blank("en")
ner = nlp.add_pipe("ner")
# Add entity labels
for _, annotations in TRAIN_DATA:
for _, _, label in annotations["entities"]:
ner.add_label(label)
# Train
nlp.begin_training()
for iteration in range(20):
random.shuffle(TRAIN_DATA)
losses = {}
batches = minibatch(TRAIN_DATA, size=2)
for batch in batches:
examples = []
for text, annotations in batch:
doc = nlp.make_doc(text)
example = Example.from_dict(doc, annotations)
examples.append(example)
nlp.update(examples, losses=losses)
# Test on new text
test_doc = nlp("The doctor recommended Aspirin 100mg for daily use.")
for ent in test_doc.ents:
print(f"{ent.text} → {ent.label_}")Output:
Aspirin → DRUG
100mg → DOSAGEIn practice, training a robust custom NER model requires hundreds to thousands of labelled examples per entity type, not just a handful. The example above illustrates the training pattern; for a production model you would use spaCy's CLI training workflow and a properly formatted training corpus.
Approach 4: Custom NER with Transformer Fine-Tuning
When you need both domain-specific entity types and state-of-the-art accuracy, fine-tuning a pretrained transformer model on your own labelled data is the most reliable path. This approach gives you the full power of a transformer's contextual understanding combined with a model adapted precisely to your vocabulary, entity types, and text style.
The standard format for transformer-based NER is BIO tagging (Beginning, Inside, Outside), where each token receives a label indicating whether it begins an entity, continues one, or belongs to none.
from transformers import (
AutoTokenizer,
AutoModelForTokenClassification,
TrainingArguments,
Trainer,
DataCollatorForTokenClassification
)
from datasets import Dataset
import numpy as np
# Define label set using BIO format
label_list = [
"O",
"B-DRUG", "I-DRUG",
"B-DOSAGE", "I-DOSAGE",
"B-CONDITION", "I-CONDITION"
]
label2id = {l: i for i, l in enumerate(label_list)}
id2label = {i: l for i, l in enumerate(label_list)}
# Load a pretrained biomedical model and tokenizer
model_name = "allenai/scibert_scivocab_uncased"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForTokenClassification.from_pretrained(
model_name,
num_labels=len(label_list),
id2label=id2label,
label2id=label2id
)
# Example training data: pre-tokenized with BIO labels
# In a real project, load from a labelled corpus (e.g. CoNLL format)
train_data = [
{
"tokens": ["Patient", "was", "prescribed", "Metformin", "500mg", "for", "diabetes"],
"ner_tags": [0, 0, 0, 1, 3, 0, 5] # B-DRUG, B-DOSAGE, B-CONDITION
},
{
"tokens": ["Administer", "Aspirin", "100mg", "daily"],
"ner_tags": [0, 1, 3, 0]
},
]
def tokenize_and_align_labels(examples):
tokenized = tokenizer(
examples["tokens"],
truncation=True,
is_split_into_words=True
)
labels = []
for i, label in enumerate(examples["ner_tags"]):
word_ids = tokenized.word_ids(batch_index=i)
label_ids = []
prev_word_id = None
for word_id in word_ids:
if word_id is None:
label_ids.append(-100) # special tokens
elif word_id != prev_word_id:
label_ids.append(label[word_id])
else:
label_ids.append(-100) # subword tokens
prev_word_id = word_id
labels.append(label_ids)
tokenized["labels"] = labels
return tokenized
dataset = Dataset.from_list(train_data)
tokenized_dataset = dataset.map(tokenize_and_align_labels, batched=True)
training_args = TrainingArguments(
output_dir="./ner_model",
num_train_epochs=3,
per_device_train_batch_size=8,
learning_rate=2e-5,
weight_decay=0.01,
save_strategy="epoch",
logging_steps=10,
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_dataset,
data_collator=DataCollatorForTokenClassification(tokenizer),
tokenizer=tokenizer,
)
trainer.train()
# Inference on new text
from transformers import pipeline
ner_pipeline = pipeline(
"ner",
model=model,
tokenizer=tokenizer,
aggregation_strategy="simple"
)
result = ner_pipeline("The patient was given Ibuprofen 200mg for acute pain.")
for entity in result:
print(f"{entity['word']:<20} {entity['entity_group']:<15} {entity['score']:.2f}")Output:
Ibuprofen DRUG 0.97
200mg DOSAGE 0.94
acute pain CONDITION 0.88The key advantage over spaCy's custom training is that the transformer backbone already understands language deeply. It has seen millions of sentences during pretraining, so your labelled data only needs to teach it your specific entity types, not language understanding from scratch. In specialised domains like biomedicine, starting from a domain-adapted model like `allenai/scibertscivocabuncased` or `dmis-lab/biobert-v1.1` gives a significant head start over a general-purpose model.
This approach requires GPU compute for training, more careful data preprocessing (handling subword tokenisation and label alignment), and a properly formatted labelled corpus. For production systems where accuracy on domain-specific entities matters, it's consistently the most reliable choice.
Approach 5: Custom NER with LLM Fine-Tuning
The most powerful, and most infrastructure-intensive, approach to custom NER is fine-tuning a large language model. LLMs bring enormous prior knowledge about the world, domain-specific vocabulary, and complex linguistic structures. Rather than outputting token-level BIO tags like smaller transformer models, they generate structured output directly in formats like JSON, making them naturally suited to span-based extraction tasks.
Instead of classifying each token sequentially, an LLM fine-tuned for NER is prompted with a clinical or domain-specific note and generates a structured list of entity spans with their types:
# Conceptual example: fine-tuned LLM producing structured NER output
# In practice this requires supervised fine-tuning (SFT) on a GPU cluster
prompt = """
Extract all named medical entities from the following clinical note.
Return a JSON list with each entity's text, type, and character offsets.
Note: Patient presents with whole body urticaria. No fever.
History of Aspirin history (-). Prednisolone 10mg prescribed.
Output:
"""
# A fine-tuned LLM would return:
output = """
[
{"text": "whole body urticaria", "type": "SYMPTOM_SIGN", "start": 37, "end": 57},
{"text": "No fever", "type": "SYMPTOM_SIGN", "start": 59, "end": 67},
{"text": "Aspirin history (-)", "type": "MEDICATION", "start": 80, "end": 99},
{"text": "Prednisolone 10mg", "type": "MEDICATION", "start": 101, "end": 118}
]
"""Notice what the LLM extracts compared to a word-level model: "whole body urticaria" instead of just "urticaria", and "Aspirin history (-)" instead of just "Aspirin". This is the key advantage of LLM-based NER. It can capture phrase-level entities that include contextual attributes, assertions, and modifiers that are clinically meaningful but would be stripped away by a word-level model.
Why This Approach Is Powerful (and Difficult to Deploy)
The appeal is obvious: an LLM already knows what a symptom is, what a drug name looks like, and how clinicians write. Fine-tuning adapts this knowledge to your specific entity schema rather than teaching entity recognition from scratch.
But this is also where many teams run into serious problems. Fine-tuning an LLM for NER is not just a modelling task. It requires multi-GPU infrastructure (training a 10B parameter model requires multiple A100 GPUs), careful data annotation at the phrase level rather than the word level, thoughtful output schema design so the model learns consistent JSON structure, and robust post-processing to validate and align the model's generated offsets against the original text.
The annotation challenge is particularly underestimated. A word-level annotation guideline ("tag the drug name") produces fundamentally different training data than a phrase-level one ("tag the drug name plus its dose, route, and negation"). The annotation span definition determines what the model learns to extract, and getting this wrong means the model either loses contextual information or learns inconsistent boundaries that hurt performance.
The Honest Take on LLM-Based NER
The results can be impressive. We have validated this approach in a clinical setting and published the findings in JAMIA Open, but without the foundations already in place, it's undeployable in practice. Clean labelled data, a consistent annotation schema, solid evaluation metrics, and the infrastructure to train and serve a large model all need to exist before LLM fine-tuning makes sense.
We'll cover LLM fine-tuning for NER in depth in a future post. For now, the progression to keep in mind is: spaCy for prototyping, transformer fine-tuning for production accuracy, and LLM fine-tuning only when phrase-level contextual extraction is genuinely required and the infrastructure is ready. Skipping steps doesn't save time. It just moves the problems later in the pipeline, where they're harder to fix.
Entity Linking
Finding an entity in text is only the first step. Entity linking (also called entity disambiguation) goes further: it connects each extracted entity to a specific entry in a knowledge base, such as Wikipedia, Wikidata, or a custom internal database.
This matters because the same surface form can refer to different things depending on context. "Apple" might refer to the technology company, the fruit, or Apple Records. "Jordan" might be a country, a person's name, or a reference to Michael Jordan. Without entity linking, you know a name appears in the text but not which real-world entity it refers to.
# spaCy's entity linker requires a custom knowledge base
# Here we demonstrate the concept with a simplified example
import spacy
nlp = spacy.load("en_core_web_md")
# spaCy's built-in entity linker can be connected to Wikipedia
# via the spacy-entity-linker or nel-wiki packages
text = "Jordan won three consecutive titles before retiring."
doc = nlp(text)
for ent in doc.ents:
print(f"{ent.text} | {ent.label_}")
# A full entity linker would resolve "Jordan" to
# Q41421 (Michael Jordan) vs Q810 (Jordan the country)
# based on contextFull entity linking pipelines are more complex to set up than basic NER, but they're essential for knowledge graph construction, question answering systems, and any application where you need to reason across documents about the same real-world entities.
NER as Part of an Information Extraction Pipeline
NER rarely operates in isolation. In most production systems, it's the first step in a broader information extraction pipeline that progressively builds up structured knowledge from unstructured text.
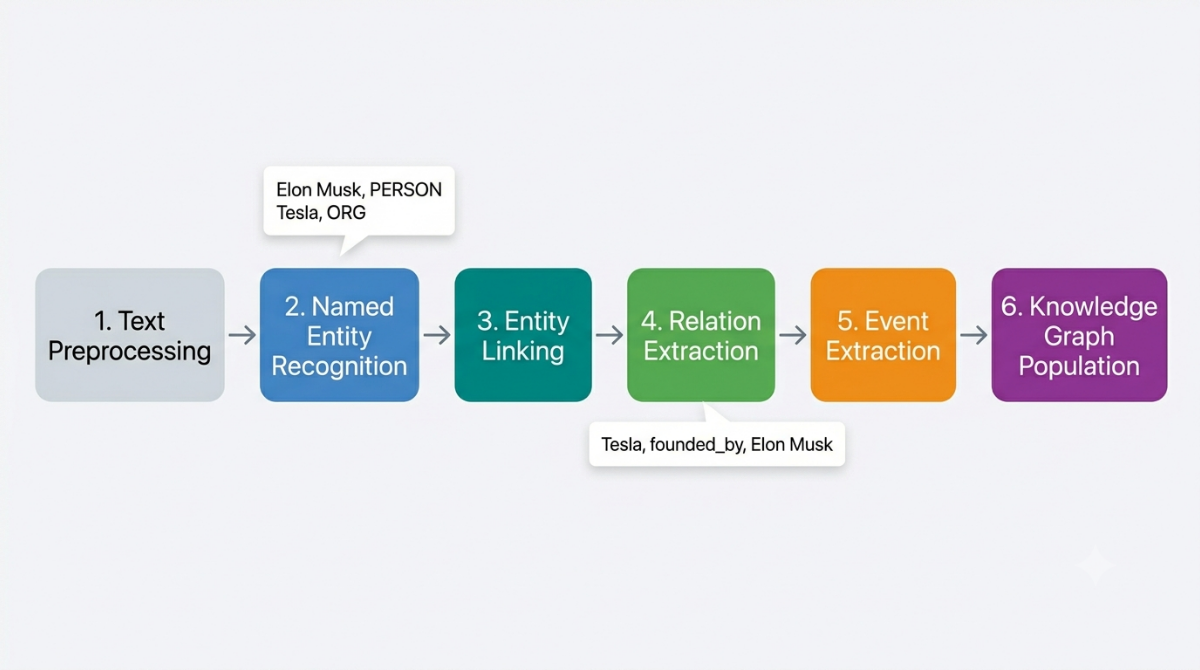
A typical pipeline looks like this:
1. Text preprocessing, clean, tokenize, and sentence-split the input 2. Named entity recognition, identify and classify entity spans 3. Entity linking, resolve entities to a knowledge base 4. Relation extraction, identify relationships between entities ("Tesla" founded_by "Elon Musk") 5. Event extraction, identify structured events (announcement, acquisition, appointment) 6. Knowledge graph population, store extracted facts as structured triples
NER provides the foundation. Without knowing which spans of text refer to specific real-world entities, the downstream steps have nothing to work with.
Which Approach Should You Use?
| Situation | Recommended approach |
|---|---|
| Quick prototype, general entity types | spaCy pretrained model (Approach 1) |
| Highest accuracy on general entities, no training | Hugging Face transformer pipeline (Approach 2) |
| Domain-specific entity types needed | Custom spaCy NER (Approach 3) |
| Previous approaches not accurate enough | Fine-tuned transformer (Approach 4) |
| Phrase-level contextual extraction required | Fine-tuned LLM (Approach 5) |
Approaches 1–3 are the right place to start. They're fast to set up, easy to debug, and often good enough for the task. If they fall short, Approach 4 is usually the best next step, fine-tuned transformers deliver high accuracy, are relatively straightforward to train, and can run on CPU in production if needed. The cost-to-accuracy trade-off is hard to beat.
LLM fine-tuning (Approach 5) is powerful but demands serious infrastructure and a mature data pipeline. It makes sense when the previous approaches have been exhausted and phrase-level, context-rich extraction is genuinely required. Don't start there.
Challenges in NER
Even strong NER models encounter difficult cases:
Ambiguity. The same word can be an entity in one context and not in another. "Apple" is an organisation in a business article and a common noun in a recipe. Models trained on general text can struggle in specialised domains where ordinary words take on entity-like meaning.
Nested entities. Some entities contain other entities. "Bank of England Monetary Policy Committee" contains both "Bank of England" (an organisation) and "England" (a location). Standard NER models typically label non-overlapping spans and can miss nested structures.
Emerging entities. New companies, people, and products are created constantly. A model trained on data from two years ago may not recognise a recently founded startup or a newly elected official.
Cross-lingual entities. Entity names are often transliterated or translated differently across languages. Multilingual NER requires models trained on diverse multilingual corpora, and performance varies significantly across languages.
Long documents. Most NER models have a maximum input length. Processing long contracts, research papers, or transcripts requires chunking the text, which can split entities that span chunk boundaries.
Where NER Is Used Today
NER is one of the most broadly deployed NLP capabilities in production systems:
News and media monitoring. Organisations track every mention of specific companies, people, and places across thousands of news sources in real time. NER extracts the entities; downstream systems count, filter, and alert.
Financial intelligence. NER extracts company names, executive names, financial figures, and dates from earnings calls, analyst reports, and regulatory filings. This structured data feeds quantitative models and compliance systems.
Legal document review. Contract analysis platforms extract parties, dates, obligations, and governing law clauses from thousands of documents, reducing manual review time significantly.
Healthcare and clinical NLP. Medical NER extracts drug names, dosages, diagnoses, symptoms, and procedures from clinical notes and research literature. This powers clinical decision support, pharmacovigilance, and medical research at scale.
Search and question answering. Search engines use NER to understand what a query is asking about. A search for "Tesla CEO" is a query about a person related to an organisation; NER helps the system understand the structure of the question.
Knowledge graph construction. Platforms like Google's Knowledge Graph and enterprise knowledge bases are built by running NER and relation extraction across large corpora to populate structured databases of facts about real-world entities.
What Comes Next
Named entity recognition shows how NLP moves from understanding what a document is about to extracting specific structured facts from it. That shift, from classification to extraction, opens up a much richer set of downstream applications.
The next post takes this further with Relation Extraction: how NLP systems identify not just which entities appear in a text, but what connections exist between them.
Learn This at Fondra Labs
This post is part of our NLP Foundations series, where we build up practical AI knowledge one concept at a time, from text processing basics all the way to the systems powering modern AI.
At Fondra Labs, we teach AI from production reality, not hype. Every topic in this series is here because it genuinely matters when you sit down to build something real.
If this was useful, explore the rest of the blog. We cover machine learning, deep learning, NLP, and the practical skills that turn understanding into building.
Frequently Asked Questions

Javier Aguirre
Teaching AI from production reality, not hype.
Build your AI Foundations
Get the free checklist that production engineers use to avoid these common RAG pitfalls.
Get the Free Guide