
You learned this in school, even if you've forgotten most of it.
Nouns are things. Verbs are actions. Adjectives describe. Adverbs modify. At some point a teacher made you underline the subject of a sentence or circle the verb, and then you moved on with your life.
But here's the thing: that grammatical knowledge you picked up in school is exactly what NLP systems need to understand language. Before a model can extract meaning from text, it needs to know what role each word is playing. Is "bank" a noun or a verb? Is "fast" an adjective or an adverb? The same word can be both, depending on context.
Part of speech tagging is how NLP systems figure that out. It's one of the foundational steps in language understanding, and it quietly powers a huge number of the NLP applications you use every day.
What Is Part of Speech?
A part of speech is a grammatical category that tells you what role a word plays in a sentence.
Every word in a sentence belongs to at least one category. The main ones you'll encounter in NLP are:
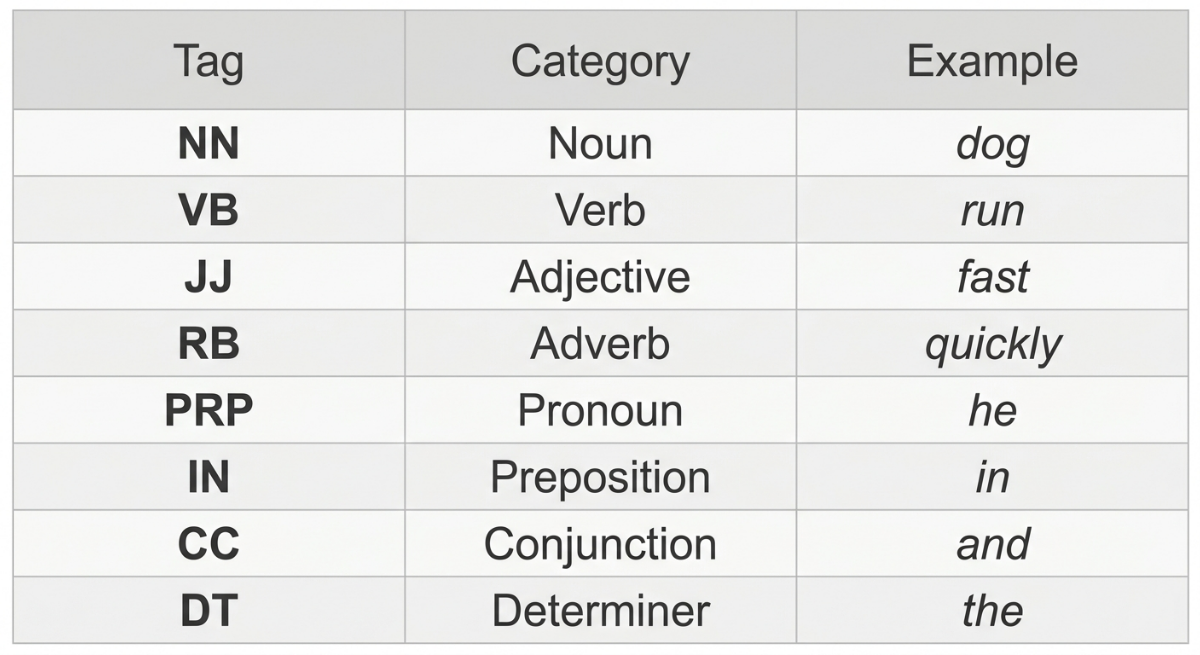
- Noun (NN): a person, place, thing, or concept. "dog," "London," "happiness"
- Verb (VB): an action or state. "run," "is," "understand"
- Adjective (JJ): describes a noun. "fast," "blue," "complicated"
- Adverb (RB): modifies a verb, adjective, or other adverb. "quickly," "very," "not"
- Pronoun (PRP): replaces a noun. "he," "she," "it," "they"
- Preposition (IN): shows relationships between words. "in," "on," "at," "between"
- Conjunction (CC): connects words or clauses. "and," "but," "or"
- Determiner (DT): introduces a noun. "the," "a," "this," "some"
In NLP, these categories are assigned short codes called Penn Treebank tags, which is why you'll often see labels like `NN`, `VBZ`, or `JJ` rather than full words. Different frameworks use slightly different tag sets, but the underlying categories are consistent.
What Is Part of Speech Tagging?
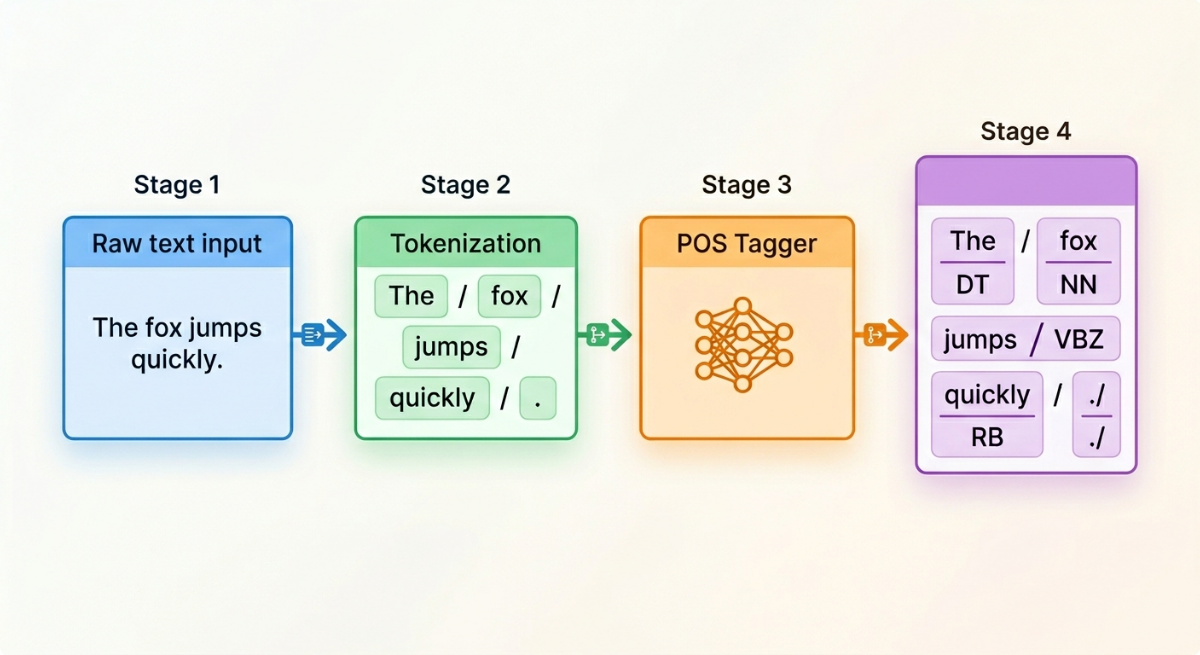
Part of speech tagging (also called POS tagging) is the process of automatically assigning a grammatical label to every word in a sentence.
Given the sentence:
"The quick brown fox jumps over the lazy dog."
A POS tagger produces:
`The/DT quick/JJ brown/JJ fox/NN jumps/VBZ over/IN the/DT lazy/JJ dog/NN`
Every word gets its tag. The model has now turned an unstructured sentence into structured grammatical information that downstream systems can reason about.
This sounds straightforward, but the hard part is ambiguity. The same word can be different parts of speech depending on context, and it happens constantly in real language.
Take the word "run":
- "I go for a run every morning." (noun)
- "I run every morning." (verb)
- "We have a run of bad luck." (noun, different meaning)
Or "fast":
- "She is a fast runner." (adjective)
- "She runs fast." (adverb)
- "He decided to fast for a day." (verb)
A POS tagger has to resolve this ambiguity correctly, using the surrounding words as context. That's where the actual intelligence lies.
Why Does POS Tagging Matter?
On its own, knowing that a word is a noun or a verb might seem like a small thing. But POS tags unlock a surprisingly wide range of downstream capabilities.
Named Entity Recognition relies on POS tags to know where to look. Proper nouns (NNP) are strong signals for names of people, places, and organisations. A system that already knows which tokens are proper nouns has a massive head start on finding entities.
Dependency parsing (figuring out the grammatical relationships between words) depends on POS tags. You can't determine whether a word is the subject or object of a verb without first knowing which words are verbs and which are nouns.
Word sense disambiguation uses POS tags to narrow down meaning. "Bank" as a noun has different senses than "bank" as a verb. Knowing the part of speech cuts the ambiguity in half before any deeper analysis begins.
Information extraction uses POS patterns to find specific structures. A rule like "find all noun phrases followed by a verb" can extract subject-action pairs from text at scale. POS tags make those patterns possible.
Search and indexing systems use POS tags to focus on content words (nouns, verbs, adjectives) and skip function words (the, a, in, of) that carry little meaning on their own.
How POS Tagging Works
Modern POS taggers use machine learning, but it helps to understand the intuition first.
The Rule-Based Approach
Early POS taggers were rule-based. Linguists wrote explicit rules: if a word ends in "-ing" and follows a modal verb like "will" or "can," tag it as a verb. These rules worked surprisingly well for formal text but broke down on informal language, new vocabulary, and edge cases.
Statistical Approaches
Statistical taggers replaced hand-written rules with probabilities learned from annotated data. Given a large corpus of text where humans have manually tagged every word, the model learns: how likely is this word to be a verb? Given the previous word was a determiner, how likely is the next word to be a noun?
Hidden Markov Models (HMMs) were the dominant approach for years. They model POS tagging as a sequence problem: what's the most likely sequence of tags given this sequence of words?
Neural Approaches
Today, most production POS taggers use neural networks, typically the same Transformer-based models used for other NLP tasks. These models learn rich contextual representations of each word and can resolve ambiguity that simpler models miss.
The key advantage is context. A neural tagger doesn't just look at a word and its immediate neighbours. It considers the entire sentence, which is exactly what's needed to correctly tag words like "run" or "fast" that change meaning depending on what surrounds them.
Syntactic Parsing: The Next Level
POS tagging tells you what each word is. Syntactic parsing goes a step further and tells you how the words relate to each other.
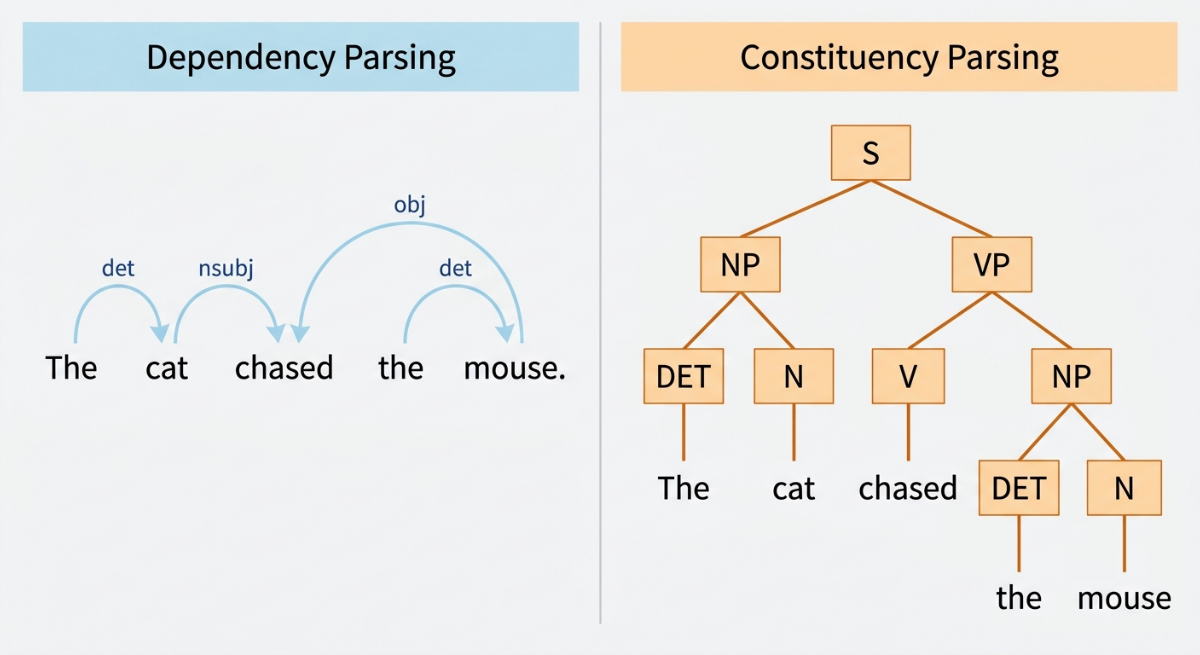
In the sentence "The cat chased the mouse," POS tagging tells you that "cat" is a noun and "chased" is a verb. Syntactic parsing tells you that "cat" is the subject of "chased" and "mouse" is the object.
There are two main types of syntactic parsing:
Dependency parsing maps out the grammatical relationships between individual words. Each word gets connected to a "head" word that it depends on, with a label describing the relationship: subject, object, modifier, and so on. This produces a tree structure called a dependency tree.
Constituency parsing breaks a sentence into nested phrases: a noun phrase, a verb phrase, a prepositional phrase. Each phrase can contain smaller phrases, producing a hierarchical tree that represents the full grammatical structure of the sentence.
Both forms of parsing build directly on POS tags. They're the next layer of structural understanding above tagging, and they're used in more complex NLP tasks like question answering, machine translation, and relation extraction.
POS Tagging in Practice with NLTK
If you want to try POS tagging yourself, NLTK is the easiest starting point in Python.
import nltk
nltk.download('averaged_perceptron_tagger')
nltk.download('punkt')
from nltk.tokenize import word_tokenize
from nltk import pos_tag
sentence = "The quick brown fox jumps over the lazy dog."
tokens = word_tokenize(sentence)
tags = pos_tag(tokens)
print(tags)
# [('The', 'DT'), ('quick', 'JJ'), ('brown', 'JJ'), ('fox', 'NN'),
# ('jumps', 'VBZ'), ('over', 'IN'), ('the', 'DT'), ('lazy', 'JJ'), ('dog', 'NN'), ('.', '.')]Four lines of meaningful code. Every token gets its tag.
For production use, spaCy is the better choice. It's faster, more accurate, and built for real-world text:
import spacy
nlp = spacy.load("en_core_web_sm")
doc = nlp("The quick brown fox jumps over the lazy dog.")
for token in doc:
print(token.text, token.pos_, token.tag_)spaCy gives you two tag levels: `pos` is a simplified universal tag (NOUN, VERB, ADJ), and `tag` is the fine-grained Penn Treebank tag (NN, VBZ, JJ). For most applications, the simplified tags are enough.
Is POS Tagging Still Used Today?
It's a fair question. With large language models able to understand language end-to-end, does anyone still bother with POS tagging?
The answer is yes, and more than you might expect.
In production NLP systems, POS tagging is rarely the star of the show. But it quietly sits inside many of the pipelines that power real applications. Here's where it still earns its place.
Clinical and legal NLP relies heavily on POS tagging. These domains often use rule-based extraction pipelines alongside machine learning, because rules are auditable and explainable in ways that a neural network isn't. When a hospital system needs to extract medication names and dosages from clinical notes, a pipeline that uses POS tags to identify noun phrases and filter by surrounding context is fast, transparent, and reliable.
Information extraction at scale still uses POS-based patterns extensively. If you need to extract all "company acquired company" events from a corpus of ten million news articles, a POS-aware pattern matcher is often faster and more controllable than a fine-tuned language model, especially when your compute budget is limited.
Lightweight NLP on constrained hardware uses POS tagging as a preprocessing step to reduce the amount of text that needs to go through expensive models. Filter out irrelevant sentences using POS patterns first, then run your heavy model only on what's left.
spaCy pipelines in production almost always include a POS tagger as a standard component. When you load a spaCy model, POS tagging happens automatically as part of the pipeline. Even if you never explicitly use the tags yourself, the downstream components like the dependency parser and named entity recogniser depend on them under the hood.
Multilingual systems often lean on POS tagging more heavily than English-only ones. For languages with complex morphology or less training data available for large models, grammatical structure provides signal that pure statistical learning can miss.
The broader point: POS tagging is a foundational layer, not a product in itself. It doesn't do anything impressive on its own. But remove it from a serious NLP pipeline and you'll quickly feel the gaps it was quietly filling.
The best NLP systems are not built from one powerful model. They are built from layers of structured understanding, each one making the next more accurate.
What Comes Next
POS tagging gives you the grammatical skeleton of a sentence. But grammar alone doesn't tell you what a sentence means.
The next step is understanding how words relate to each other in terms of meaning, not just structure. That leads us to Dependency Parsing, where we look at how NLP models map out the relationships between words: who did what to whom, what modifies what, and how the parts of a sentence connect into a coherent whole.
Learn This at Fondra Labs
This post is part of our NLP Foundations series, where we build up practical AI knowledge one concept at a time, starting from the basics and going all the way to production-grade systems.
At Fondra Labs, we teach AI from production reality, not hype. Every topic in this series is chosen because it genuinely matters when you sit down to build something real.
If this was useful, explore the rest of the blog. We cover everything from machine learning fundamentals to deep learning architectures, NLP pipelines, and the practical skills that turn understanding into building.
Frequently Asked Questions

Javier Aguirre
Teaching AI from production reality, not hype.
Build your AI Foundations
Get the free checklist that production engineers use to avoid these common RAG pitfalls.
Get the Free Guide